Nuevos modelos de OpenAI: o3, o4-mini y 04-mini-high
OpenAI ha lanzado tres nuevos modelos de razonamiento para ChatGPT (o3, o4-mini y o4-mini-high, con el nombre en clave Phoenix).
El 16 de abril de 2025 OpenAI ha presentado OpenAI o3 y o4-mini, sus modelos más inteligentes y con más capacidades.
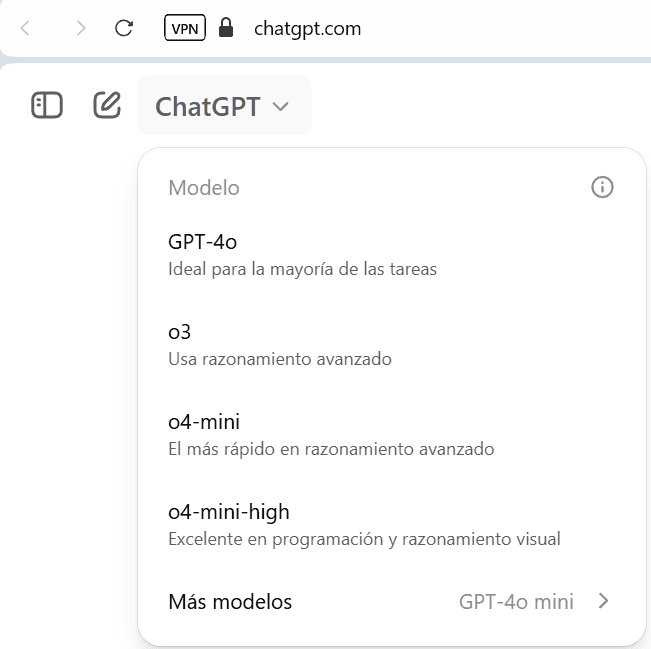
o3 reemplaza a o1, y o4-mini y o4-mini-high reemplazan a o3-mini y o3-mini-high; todos pueden usar herramientas de ChatGPT como Python, Búsqueda, Canvas, carga de archivos, análisis de imágenes e ImageGen, incluyendo «pensamientos estructurados» detallados que contienen pasos de razonamiento explícitos, resultados de búsqueda, código Python y resúmenes colapsables, y ahora soportan razonamiento visual avanzado e imágenes nativas con puntuaciones de referencia superiores.
Los modelos son más precisos, eficientes y rentables que antes, establecen resultados de vanguardia en tareas de codificación, matemáticas y visuales, y se benefician de una seguridad mejorada a través de un nuevo entrenamiento de rechazo, detección avanzada de riesgos y revisiones independientes que confirman que se mantienen por debajo de todos los umbrales de seguridad de alto riesgo.
Los usuarios de ChatGPT Plus, Pro y Team tienen acceso ahora, Enterprise y Edu en una semana, los usuarios gratuitos pueden probar o4-mini en modo Think; la API y la API de Respuestas soportan o3 y o4-mini para razonamiento avanzado con resúmenes de razonamiento (el uso de herramientas llegará pronto); o3-pro con soporte de herramientas se lanzará en unas semanas.
En la API, o4-mini y o3 ofrecen una ventana de contexto de 200,000 tokens, hasta 100,000 tokens de salida, y tienen un límite de conocimiento hasta el 1 de junio de 2024.
Codex CLI ahora también está disponible como un agente de codificación basado en terminal de código abierto que trae razonamiento de código a nivel de ChatGPT, ejecución de código en vivo, soporte multimodal y automatización segura en un entorno aislado al terminal, con un programa de subvenciones de $1 millón disponible para apoyar proyectos de código abierto que utilicen Codex CLI y modelos de OpenAI.
Visión detallada de los modelos OpenAI o3 y o4-mini
Introducción
Los modelos OpenAI o3 y o4-mini combinan razonamiento de vanguardia con capacidades completas de herramientas, incluyendo navegación web, Python, análisis de imágenes y archivos, generación de imágenes, canvas, automatizaciones, búsqueda de archivos y memoria. Estos modelos son especialmente competentes en resolver desafíos complejos de matemáticas, codificación y ciencia, demostrando una fuerte percepción y análisis visual.
Datos y Entrenamiento del Modelo
Los modelos de la serie o están entrenados con aprendizaje por refuerzo a gran escala en cadenas de pensamiento, lo que les permite refinar su proceso de pensamiento, probar diferentes estrategias y reconocer errores. Esto les ayuda a seguir directrices específicas y políticas de seguridad, proporcionando respuestas más útiles y resistiendo intentos de eludir las reglas de seguridad.
Desafíos y Evaluaciones de Seguridad
Contenido No Permitido
Se evaluó que los modelos no cumplan con solicitudes de contenido dañino y que no rechacen en exceso solicitudes benignas relacionadas con temas de seguridad. Los modelos o3 y o4-mini mostraron un rendimiento comparable al modelo o1 en estas evaluaciones
Jailbreaks
Se evaluó la robustez de los modelos frente a intentos de jailbreak, es decir, prompts adversariales que intentan eludir las negativas del modelo para producir contenido no permitido. Los modelos o3 y o4-mini mostraron un rendimiento similar al modelo o1
Alucinaciones
Se evaluaron las alucinaciones en los modelos o3 y o4-mini utilizando conjuntos de datos de preguntas factuales y sobre personas. El modelo o4-mini mostró un rendimiento inferior en comparación con o1 y o3 en la evaluación PersonQA, debido a su menor conocimiento del mundo
Evaluaciones Multimodales
Los modelos o3 y o4-mini mejoraron en la negativa a permitir contenido que viole las políticas de OpenAI en entradas multimodales (texto e imagen combinados).
Evaluaciones de Identificación de Personas e Inferencias No Fundamentadas
Se evaluó la capacidad de los modelos para identificar personas en fotos y crear inferencias no justificadas. Los modelos o3 y o4-mini mostraron un rendimiento comparable o mejor que el modelo o1.
Evaluaciones de Equidad y Sesgo
Se probó a los modelos en la evaluación BBQ y en la evaluación de equidad en primera persona. Los modelos o3 y o4-mini mostraron un rendimiento similar al modelo o1 en estas evaluaciones
Evaluaciones de Ciberseguridad
Se evaluaron las capacidades de los modelos para resolver desafíos de ciberseguridad ofensiva. Los modelos o3 y o4-mini mostraron mejoras en comparación con modelos anteriores, pero no alcanzaron el umbral alto de capacidad autónoma.
Evaluaciones de Auto-mejora de IA
Los modelos o3 y o4-mini demostraron un rendimiento mejorado en tareas de ingeniería de software y investigación de IA relevantes para los riesgos de auto-mejora de IA. Sin embargo, en tareas más abiertas y del mundo real, los modelos mostraron un rendimiento pobre.
Salvaguardias
Se han implementado nuevas mitigaciones y técnicas de alineación para abordar los riesgos potenciales de seguridad, incluyendo monitoreo mejorado y técnicas de alineación razonada.
Rendimiento Multilingüe
Los modelos o3 y o4-mini mostraron mejoras en capacidad multilingüe en comparación con modelos anteriores, evaluados en 13 idiomas.
Conclusión
Los modelos OpenAI o3 y o4-mini representan avances significativos en capacidades de razonamiento y uso de herramientas. Las evaluaciones de seguridad indican que estos modelos se desempeñan generalmente a la par o mejor que los modelos anteriores en la negativa a producir contenido dañino y en la resistencia a intentos de jailbreak
Información basada en la publicación en Twitter/X de Tibor Blaho (Lead Engineer at
AIPRM and Link Research Tools) que a su vez se basa en estas fuentes: Introducing OpenAI o3 and o4-mini, pensar con imágenes, OpenAI o3 and o4-mini System Card, OpenAI o3 and o4-mini System Card, Reasoning models y GitHub OpenAI Codex.