¿Qué hacen realmente los modelos LLM?
Para entender como funcionan los LLMs, te recomiendo leer el libro «Foundations of Large Language Models» de Tong Xiao y Jingbo Zhu publicado en 2025.
Y si alguna vez te has preguntado qué hay detrás de herramientas como ChatGPT, aquí te resumo su contenido.
🧠 ¿Qué es el preentrenamiento?
En lugar de enseñar a un modelo a resolver una tarea concreta con datos etiquetados (como clasificar tuits), los LLMs se entrenan con enormes cantidades de texto sin etiquetar. Así, aprenden por sí solos los patrones del lenguaje. A esto se le llama aprendizaje autosupervisado.
Existen tres estrategias de preentrenamiento:
- No supervisado: el modelo aprende sin etiquetas.
- Supervisado: aprende a partir de tareas con etiquetas.
- Autosupervisado: el modelo genera sus propias etiquetas a partir del texto (por ejemplo, prediciendo palabras ocultas).
Los LLMs utilizan esta última, y es la más potente.
🧩 ¿Cómo funciona el aprendizaje autosupervisado?
Imagina la frase:
“A quien madruga, Dios le ayuda.”
Ocultamos algunas palabras:
“A quien [MASK], Dios le [MASK].”
El modelo debe rellenar los huecos. No necesita etiquetas externas: el propio texto es la supervisión.

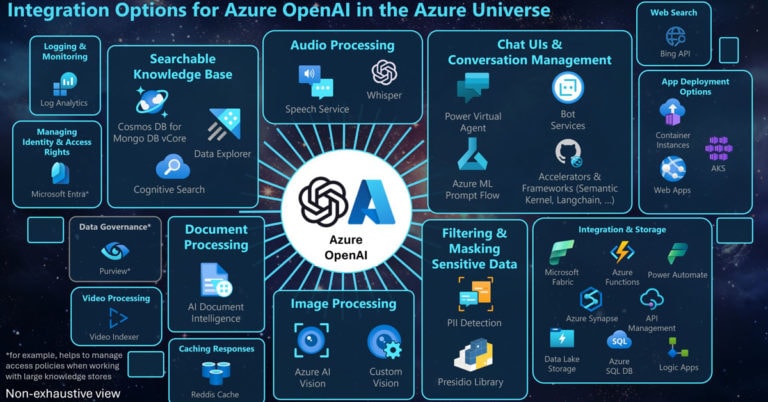
🏗️ Tipos de arquitecturas
Este enfoque ha dado lugar a tres tipos principales de arquitecturas:
- Solo codificador (BERT): entiende texto.
- Solo decodificador (GPT): genera texto.
- Codificador-decodificador (T5, BART): transforma texto en otro texto.
Cada una tiene sus puntos fuertes:
- GPT es excelente generando texto.
- BERT es ideal para tareas de clasificación.
- T5 puede hacer ambas cosas gracias a su enfoque “texto a texto”.
🔍 Veamos cada una en detalle
🔸 GPT (solo decodificador)
Se entrena para predecir la siguiente palabra dada una secuencia anterior:
“El gato se sentó en la [MASK]” → “alfombra”
Esto se llama modelado causal del lenguaje.
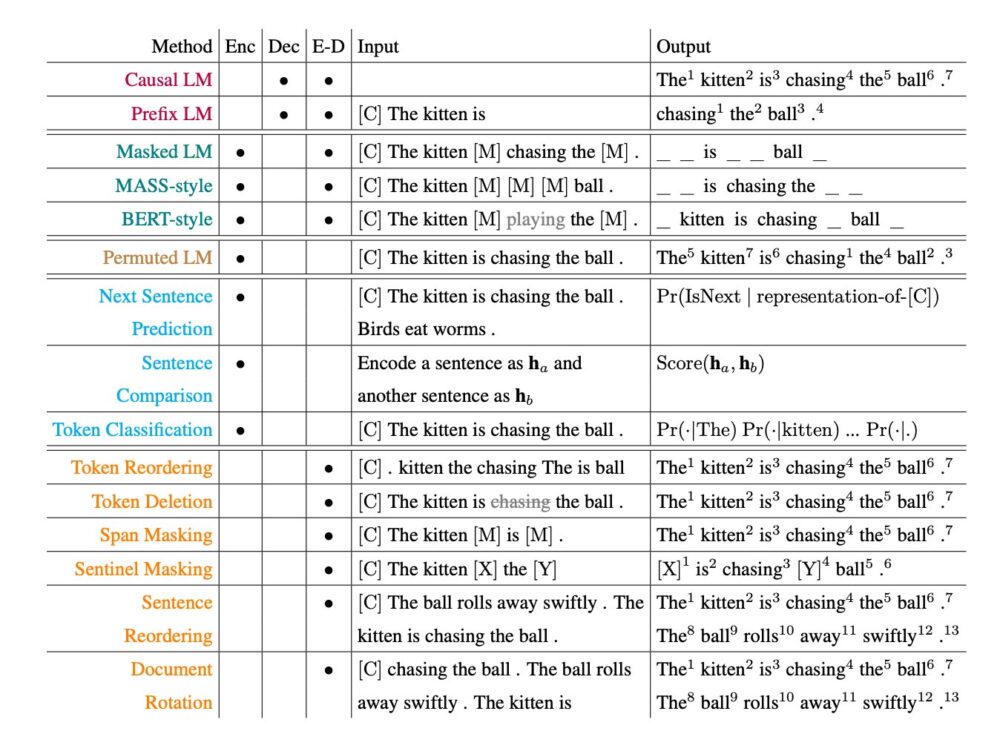
🔸 BERT (solo codificador)
Lee toda la frase, oculta palabras aleatorias y trata de reconstruirlas.
Permite usar contexto bidireccional (izquierda y derecha del [MASK]), lo que lo hace ideal para clasificación de frases.
🔸 T5 (codificador-decodificador)
Convierte cualquier tarea de lenguaje en una tarea de texto a texto.
Ejemplos:
- “Traducir inglés a alemán: hello” → “hallo”
- “Clasificar sentimiento: odio esto” → “negativo”
🛠️ ¿Qué pasa después del preentrenamiento?
Hay dos caminos:
- Ajuste fino (fine-tuning): entrenar más con datos etiquetados específicos.
- Prompting: diseñar entradas inteligentes para guiar al modelo.
El prompting es lo que hace que los LLMs parezcan mágicos.
✨ Técnicas de prompting
- Cadena de pensamiento: “Pensemos paso a paso…”
- Descomposición de problemas: dividir un problema grande en partes pequeñas.
- Auto-revisión: el modelo critica y mejora su propia respuesta.
- RAG (Retrieval-Augmented Generation): el modelo busca información externa.

Todo esto es posible porque los modelos han aprendido a predecir la siguiente palabra una y otra vez, hasta interiorizar la estructura del lenguaje, patrones de razonamiento y conocimiento del mundo.
🧭 ¿Y cómo se alinean con los valores humanos?
No basta con que sean inteligentes. Deben ser útiles, seguros y honestos.
Para ello se usan:
- Ajuste fino supervisado (SFT): entrenar con respuestas humanas.
- Aprendizaje por refuerzo con retroalimentación humana (RLHF): entrenar un modelo de recompensa que prefiera buenas respuestas.
Métodos más recientes como DPO (Direct Preference Optimization) están ganando popularidad por ser más estables.
⚡ ¿Y cómo se ejecutan eficientemente?
- Decodificación inteligente (top-k, nucleus sampling)
- Caché de resultados anteriores
- Agrupación de solicitudes
- Mejoras en memoria y posiciones para contextos largos
🧾 En resumen
Los LLMs funcionan porque:
- Aprenden de texto masivo mediante autosupervisión.
- Usan Transformers para modelar secuencias.
- Se pueden ajustar o guiar para cualquier tarea.
- Se alinean con preferencias humanas.
- Están optimizados para respuestas rápidas.
Son máquinas de razonamiento textual de propósito general.
Información basada en el libro «Foundations of Large Language Models» de Tong Xiao y Jingbo Zhuy completada con la publicación en Twitter / X de Alex Prompter del 26 de julio.