Cómo gpt-oss va a redefinir el mercado de la IA
Los nuevos modelos gpt-oss suponen una ruptura con los LLM cerrados de OpenAI, marcando un giro estratégico.
OpenAI ha sorprendido al ecosistema de inteligencia artificial con el lanzamiento de gpt-oss, su primera serie de modelos de lenguaje con pesos abiertos desde GPT-2. Esta nueva familia incluye dos modelos exclusivamente de texto: gpt-oss-120b y gpt-oss-20b, ambos disponibles bajo la licencia Apache 2.0, lo que marca un giro estratégico que desafía directamente el mercado actual y el propio modelo de negocio de la compañía.
En resumen, lo que OpenAI ha publicado como open-source es:
- Un modelo de 20B para PC y portátiles: El modelo mediano es ejecutable con 16GB de VRAM (bastante apto para muchos PCs) y es comparable a o3-mini.
- 21.000 millones de parámetros.
- El diseño Mixture-of-Experts mantiene activos 3.600 millones de parámetros.
- Un modelo de 120B para datacenters y PCs high-end: El modelo grande es ejecutable con 80GB de VRAM (poco asequible para la mayoría) y es el modelo comparable con o4-mini.
- 117.000 millones de parámetros.
- El diseño Mixture-of-Experts mantiene activos 5.100 millones de parámetros.
Son modelos solo de texto, centrados en el razonamiento, compatibles con técnicas como chain-of-thought y con capacidad de ajuste.
gpt-oss es un gran avance: se trata de un modelo de razonamiento de última generación con pesos abiertos, que ofrece un rendimiento sólido en escenarios reales comparable al de o4-mini, y que puedes ejecutar localmente en tu propio ordenador (o incluso en tu móvil si usas una versión más pequeña). Creemos que es el mejor y más accesible modelo abierto del mundo.
Nos entusiasma poner este modelo —resultado de miles de millones de dólares en investigación— a disposición de todo el mundo, para que la IA llegue a tantas personas como sea posible. Creemos que generará mucho más bien que mal; por ejemplo, gpt-oss-120b rinde de forma similar a o3 en cuestiones complejas de salud. Hemos trabajado intensamente para mitigar los problemas de seguridad más graves, especialmente en lo relativo a la bioseguridad. Los modelos gpt-oss ofrecen un rendimiento comparable al de nuestros modelos más avanzados en pruebas internas de seguridad.
Creemos en el empoderamiento individual. Aunque pensamos que la mayoría de la gente preferirá usar servicios cómodos como ChatGPT, también defendemos que las personas puedan controlar y modificar directamente su propia IA cuando lo necesiten, y los beneficios en privacidad son evidentes.
Como parte de esta visión, tenemos muchas esperanzas de que esta publicación impulse nuevas formas de investigación y la creación de nuevos tipos de productos. Esperamos un aumento significativo en el ritmo de innovación en nuestro campo, y que muchas más personas puedan realizar trabajos importantes que antes no estaban a su alcance.
La misión de OpenAI es garantizar que la AGI beneficie a toda la humanidad. Por ello, nos alegra que el mundo pueda construir sobre una pila de IA abierta creada en Estados Unidos, basada en valores democráticos, disponible de forma gratuita para todos y con beneficios amplios.
Sam Altman – CEO de OpenAI – 5 de agosto de 2025
Bajo el capó de gpt-oss
Ambos modelos están construidos sobre una arquitectura Transformer con diseño Mixture-of-Experts (MoE), una técnica que permite enrutar cada entrada solo a unos pocos expertos relevantes, reduciendo drásticamente la carga computacional.
- gpt-oss-120b: 117 mil millones de parámetros totales, 128 expertos, 4 activos por token (5.1B parámetros activos).
- gpt-oss-20b: 21 mil millones de parámetros, 32 expertos, 4 activos por token (3.6B parámetros activos).
Ambos admiten contextos de hasta 128.000 tokens y emplean técnicas como MQA agrupado y RoPE para mejorar la eficiencia.
OpenAI también ha liberado su tokenizador o200k_harmony, aunque la publicación no incluye datos de entrenamiento, código ni modelos base originales, lo que limita su utilidad para investigadores que deseen replicar o modificar el proceso de entrenamiento.
Preentrenamiento y arquitectura del modelo
Los modelos gpt-oss se entrenaron utilizando nuestras técnicas más avanzadas de preentrenamiento y posentrenamiento, con un enfoque especial en el razonamiento, la eficiencia y la utilidad en entornos reales, abarcando una amplia variedad de contextos de implementación.
Cada modelo es un Transformer que utiliza la Mixture-of-Experts (MoE) para reducir el número de parámetros activos necesarios para procesar la entrada. gpt-oss-120b activa 5100 millones de parámetros por token, mientras que gpt-oss-20b activa 3600 millones. Los modelos tienen, respectivamente, 117 mil millones y 21 mil millones de parámetros en total. Los modelos utilizan patrones de atención alterna entre atención densa y atención dispersa localmente acotada, similares a los de GPT‑3. Para mejorar la eficiencia en inferencia y uso de memoria, los modelos también utilizan grouped multi-query attention, con un tamaño de grupo de 8. Se utliza Rotary Positional Embedding (RoPE) para la codificación posicional y se ofrece compatibilidad nativa con longitudes de contexto de hasta 128 k.
Los modelos están entrenados con un conjunto de datos de alta calidad, mayoritariamente en inglés y compuesto solo por texto, con un enfoque en disciplinas STEM, programación y conocimiento general.
Posentrenamiento
Los modelos se sometieron a un posentrenamiento mediante un proceso similar al utilizado para o4-mini, que incluye una etapa de ajuste supervisado y una fase de aprendizaje por refuerzo de alto cómputo. El objetivo fue alinear los modelos con la especificación de modelos de OpenAI Model Spec y enseñarle a aplicar el razonamiento en cadena (CoT1) y el uso de herramientas antes de generar una respuesta. Al utilizar las mismas técnicas que los modelos propietarios de razonamiento de última generación (SoTA), los modelos demuestran capacidades excepcionales tras el postentrenamiento.
Igual que los modelos de razonamiento de la serie o de OpenAI en la API, estos dos modelos con pesos accesibles permiten ajustar el esfuerzo de razonamiento en tres niveles: bajo, medio y alto, lo que supone un equilibrio entre latencia y rendimiento. Los desarrolladores pueden ajustar fácilmente el esfuerzo de razonamiento con una sola frase en el mensaje del sistema.
Un nuevo referente en benchmarks abiertos
El modelo gpt-oss-120b iguala o supera al modelo cerrado o4-mini de OpenAI en benchmarks clave como MMLU, TauBench y el exigente Humanity’s Last Exam. Además, destaca en matemáticas competitivas (AIME 2024/2025) y en consultas sanitarias (HealthBench).
Por su parte, gpt-oss-20b se compara favorablemente con o3-mini, lo que lo convierte en una opción sólida para aplicaciones locales o en dispositivos.
Ambos modelos están diseñados para flujos de trabajo agentivos, con buena capacidad de seguimiento de instrucciones y uso de herramientas como búsqueda web o ejecución de código. Sin embargo, carecen de capacidades multimodales, por lo que quienes necesiten procesamiento de imágenes o audio deberán seguir usando la API de OpenAI.
Licencia permisiva y accesibilidad empresarial
La elección de la licencia Apache 2.0 permite el uso comercial sin restricciones, a diferencia de la licencia de Meta para Llama, que exige acuerdos adicionales para servicios con más de 700 millones de usuarios activos.
Esto abre la puerta a su adopción en sectores regulados como finanzas y sanidad, donde la privacidad de los datos es crítica. Además, los modelos están optimizados para despliegues eficientes:
- gpt-oss-120b puede ejecutarse en una sola GPU de 80GB.
- gpt-oss-20b requiere solo 16GB de memoria.
OpenAI ha colaborado con plataformas como Azure, AWS, Hugging Face, y con fabricantes como NVIDIA y AMD para facilitar su adopción.
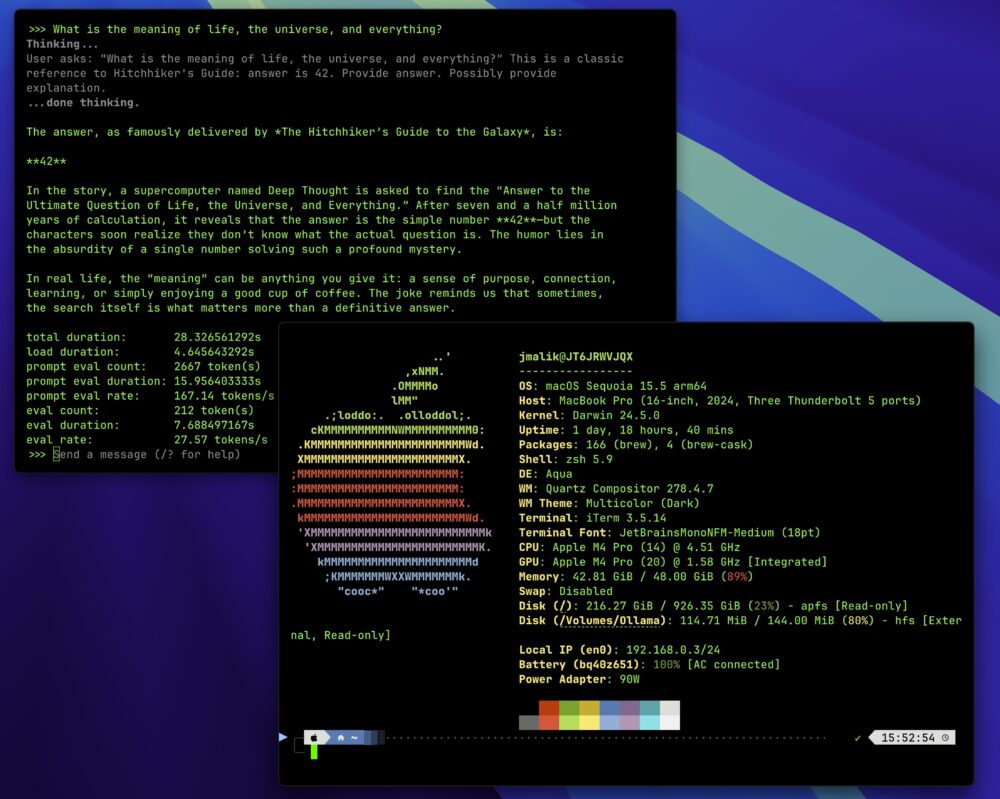
Ejecución del modelo en un MAC con M4
GPT-OSS-20b ejecutándose a ~30 tokens/segundo de media en un Mac M4 con 48GB, localmente vía Ollama:
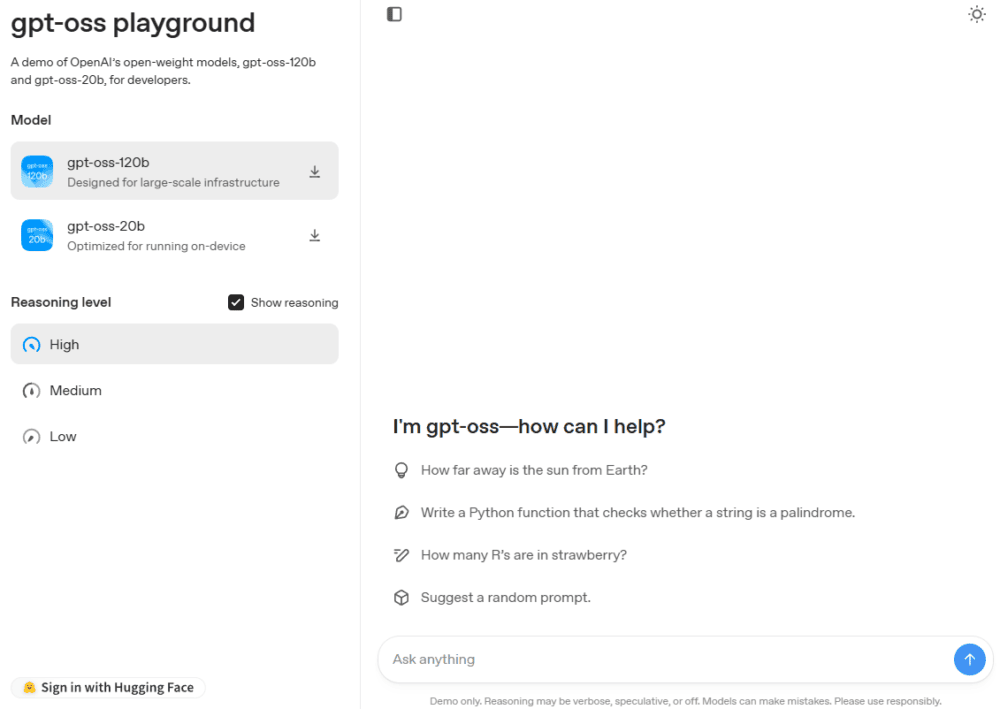
¿Lo quieres probar sin tener que instalarlo en local?
En gpt-oss playground puedes probar los dos modelos:
¿Por qué ahora? El cálculo estratégico de OpenAI
Este movimiento responde a la presión del ecosistema open-source, especialmente por modelos de alto rendimiento provenientes de China como DeepSeek-R1 y Alibaba. De hecho, OpenAI anunció su intención de abrir modelos justo después del lanzamiento de DeepSeek-R1.
Aunque gpt-oss podría canibalizar parte del mercado de OpenAI, especialmente en modelos no frontera como o4-mini, la compañía reconoce que muchos clientes ya combinan sus modelos de pago con alternativas abiertas.
Con gpt-oss, OpenAI busca recuperar a esos usuarios y mantenerlos dentro de su ecosistema, asegurando compatibilidad futura con sus modelos cerrados.
En un sector tan competitivo, liberar modelos que cuestan cientos de millones de dólares en entrenamiento no es un acto de altruismo, sino una jugada estratégica para seguir liderando el futuro de la IA.
Información basada en la publicación Introducing gpt-oss de OpenAI, los modelos abiertos de OpenAI, la prueba de velocidad de Jatin (@jatinkrmalik) compartida en Twitter, el anuncio de Sam Altman en X/Twitter «gpt-oss is a big deal» y la demo que se puede usar en gpt-oss playground.
- Cadena de pensamiento (CoT): Las investigaciones recientes de OpenAI han demostrado que monitorizar el razonamiento en cadena (CoT) de un modelo puede ser útil para detectar comportamientos indebidos, siempre que el modelo no se haya entrenado con supervisión directa para alinear dicho razonamiento. Esta perspectiva también es compartida por otras personas del sector. Siguiendo los principios desde el lanzamiento de la vista previa de OpenAI o1, no se aplica supervisión directa sobre el razonamiento en cadena (CoT) en ninguno de los modelos gpt-oss. En OpenAI creen que esto es fundamental para supervisar el mal comportamiento, el engaño y el uso indebido del modelo. Su esperanza es que, al lanzar un open model con razonamiento en cadena no supervisado, los desarrolladores e investigadores tengan la oportunidad de investigar e implementar sus propios sistemas de supervisión de CoT.
Los desarrolladores no deberían mostrar directamente las cadenas de razonamiento (CoTs) a los usuarios en sus aplicaciones. Pueden contener contenido inventado o perjudicial, incluido lenguaje que no se ajusta a las políticas de seguridad estándar de OpenAI, así como información que el modelo ha sido instruido explícitamente para no incluir en la respuesta final. ↩︎