

8 LLMs locales en DGX Spark: Qwen contra todos
En inteligencia artificial caemos en comparativas simples: China vs. Estados Unidos, open source vs. modelos cerrados, tamaño vs. calidad.
Pero después de evaluar 8 modelos open source ejecutándose en local sobre NVIDIA DGX Spark, la conclusión es bastante más concreta: no es China contra EE. UU.; es Qwen contra todos los demás.
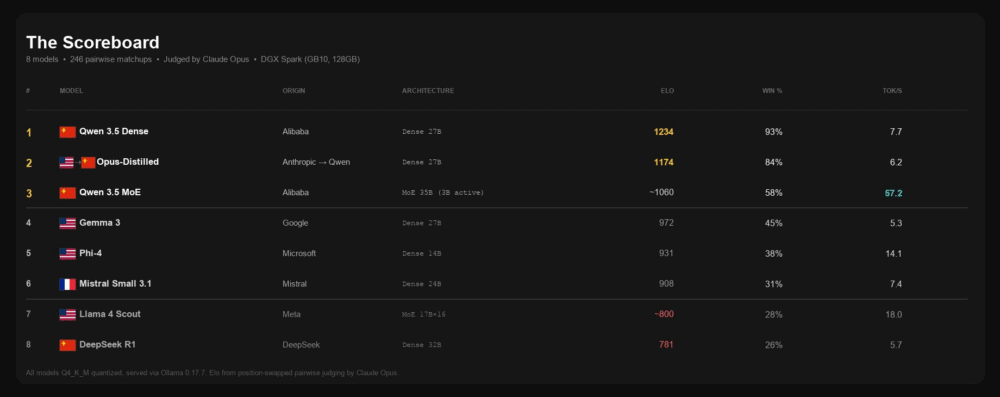
Los tres mejores modelos del benchmark comparten ADN Qwen. El primero fue Qwen 3.5 Dense. El segundo, un modelo destilado que combina el conocimiento de Claude Opus con arquitectura Qwen. El tercero, Qwen 3.5 MoE, la variante orientada a velocidad. Mientras tanto, algunos nombres muy mediáticos quedaron muy por debajo de lo esperado: DeepSeek terminó último y Llama 4 Scout, la gran apuesta open source de Meta, ofreció una relación calidad/tamaño difícil de justificar.
Pero este análisis no va de ganadores absolutos. Va de algo más útil: qué modelo merece la pena ejecutar en local para cargas reales de producción.
El objetivo del benchmark
Se probaron 8 modelos open source en igualdad de condiciones sobre NVIDIA DGX Spark, con 246 enfrentamientos por pares, 6 tareas de producción reales y 3 capas de evaluación.
Nada de benchmarks sintéticos. Nada de tests diseñados para lucirse. Nada de “sensaciones”.
Solo tareas que se parecen a las que usan agentes autónomos en producción 24/7: síntesis, clasificación, generación de código, comprensión multilingüe, razonamiento cuantitativo y redacción larga.
La pregunta era muy simple: ¿Qué modelos open source merece la pena ejecutar en esta máquina para trabajo real?

El hardware: DGX Spark como plataforma de inferencia local seria
La prueba se realizó sobre NVIDIA DGX Spark, una workstation compacta de sobremesa basada en el superchip GB10 Grace Blackwell, con arquitectura ARM (aarch64) y 128 GB de memoria unificada CPU+GPU.
No estamos hablando de una GPU de centro de datos, sino de una máquina pensada para acercar la inferencia local avanzada a desarrolladores y equipos pequeños. En este caso, conectada por red local vía SSH y sirviendo todos los modelos a través de Ollama 0.17.7, cuantizados en Q4_K_M cuando aplicaba.
La configuración fue idéntica para todos. Mismo hardware. Mismo stack de serving. Misma cuantización. La única variable era el modelo.
Los 8 modelos evaluados
Modelos de 6 organizaciones, 4 países y 2 arquitecturas distintas.
Modelos densos
En los modelos densos, todos los parámetros participan en cada token.
- Qwen 3.5 (27B, 17GB) 🇨🇳 El buque insignia de Alibaba.
- Opus-Distilled (27B, 16GB) 🇺🇸🇨🇳 Anthropic’s Claude Opus, destilado sobre arquitectura Qwen. E hoibrido: inteligencia estadounidense y arquitectura china
- Gemma 3 (27B, 17GB) 🇺🇸 La principal propuesta open-weight de Google.
- Phi-4 (14B, 9.1GB) 🇺🇸 El modelo compacto de Microsoft.
- Mistral Small 3.1 (24B, 15GB) 🇫🇷 La apuesta europea de Mistral.
- DeepSeek R1 (32B, 19GB) 🇨🇳 El modelo especializado en razonamiento de DeepSeek.
Modelos MoE (Mixture of Experts)
En los modelos MoE, solo una parte de los parámetros se activa en cada token.
- Qwen 3.5 MoE (35B total, 3B active, 24GB) 🇨🇳 — Misma base Qwen, optimizada para velocidad.
- Llama 4 Scout (17B x 16 experts, 67GB) 🇺🇸 —El lanzamiento más reciente de Meta en el momento de la prueba.
Además, se utilizó Claude Opus vía API como benchmark de referencia de calidad máxima.
Las tareas: evaluación sobre trabajo real
En lugar de usar tests como MMLU o HumanEval, se diseñaron 6 tareas alineadas con casos de uso reales:
- T1 Síntesis: Dado un conjunto de señales informativas no relacionadas entre sí, el modelo debía identificar el patrón estructural que las conecta, sin limitarse a resumir cada una por separado.
- T2 Clasificación: Clasificación de afirmaciones en dos grupos: las que refuerzan conocimiento experto y las que desafían intuiciones previas. Aquí lo que se mide es calibración epistemológica.
- T3 Código: Generación de un script en Python para transformar datos JSONL desordenados en un informe en Markdown. No bastaba con que el código “pareciera correcto”: tenía que ejecutarse.
- T4 Comprensión en chino: Lectura de un paper académico en chino sobre emergencia en LLMs y resumen en inglés del argumento central. Se medía profundidad multilingüe, no simple traducción.
- T5 Razonamiento cuantitativo: Cálculo de tamaños de apuesta con criterio de Kelly sobre tres mercados predictivos, seguido de explicación del vínculo entre certeza y tamaño de posición.
- T6 Redacción rápida: Generación de un ensayo de 500 palabras sobre memoria persistente para agentes de IA. Aquí importaban tanto velocidad como calidad mínima sostenida.
La metodología: tres capas de evaluación
Uno de los elementos más interesantes del benchmark es que no se quedó en “ejecutar y puntuar”.
Rendimiento bruto
Todos los modelos resolvieron las 6 tareas. Se midieron tokens por segundo y se revisó la calidad cualitativa de la salida.
Elo por comparación par a par
Cada salida fue enfrentada contra la de todos los demás modelos, por pares, y evaluada por Claude Opus como juez. Para evitar sesgos de orden, cada comparación se hizo dos veces invirtiendo posiciones.
En total: 246 enfrentamientos.
Esto permitió construir un sistema Elo, similar al de ajedrez, en lugar de depender de puntuaciones arbitrarias o autoevaluaciones implícitas.
El sistema Elo
El sistema Elo es un método para ordenar participantes en función de enfrentamientos directos. Nació en ajedrez, pero sirve para cualquier escenario donde A compite contra B y hay un ganador, un perdedor o un empate.
En tu benchmark, en vez de preguntar “¿qué nota absoluta merece cada modelo?”, la lógica es: “cuando comparo la respuesta del modelo A contra la del modelo B, ¿cuál gana?”
A partir de muchas comparaciones de ese tipo, Elo construye un ranking.
La idea básica: Cada modelo tiene una puntuación Elo.
- Si un modelo con Elo alto gana a uno con Elo bajo, apenas sube, porque era lo esperable.
- Si un modelo con Elo bajo gana a uno con Elo alto, sube bastante, porque ha habido sorpresa.
- Si un favorito pierde, baja bastante.
Es decir, Elo no solo mira quién gana, sino contra quién gana.
En modelos de lenguaje, muchas veces es difícil dar una “nota absoluta” fiable a una respuesta. Pero sí es más fácil plantear esto:
- Respuesta de modelo A
- Respuesta de modelo B
- Un juez compara ambas
- Decide cuál es mejor para una tarea concreta
Eso convierte la evaluación en una serie de duelos uno contra uno. Y ahí Elo funciona muy bien porque:
- evita depender de una rúbrica única demasiado rígida,
- convierte muchas comparaciones subjetivas en un ranking estable,
- permite ver no solo quién gana más, sino contra quién gana.
Así, en lugar de decir “este modelo sacó un 8,2”, dices algo más robusto: “este modelo gana sistemáticamente a otros modelos fuertes en comparaciones directas”.
Qué significa una diferencia de Elo como regla intuitiva:
- +50 Elo: ventaja pequeña pero real
- +100 Elo: ventaja clara
- +200 Elo: superioridad muy marcada
- +400 Elo: dominio aplastante
No es una ley rígida, pero sirve para interpretar distancias.
Ventajas del sistema Elo:
- Es comparativo, no depende tanto de una nota absoluta.
- Es sensible al nivel del rival.
- Escala bien cuando hay muchos enfrentamientos.
- Es fácil de actualizar al añadir nuevos resultados.
Perturbation testing
Aquí está probablemente la parte más valiosa del marco de evaluación.
Se mantuvo la misma estructura de tarea, pero cambiando dominio, contexto o números. Por ejemplo: misma lógica de síntesis, pero en otra industria; mismo problema matemático, pero con odds distintas.
La idea es sencilla: si un modelo acierta el ejemplo original pero falla cuando cambias ligeramente la superficie del problema, entonces no estaba razonando; estaba replicando patrones.
Es una capa que muchos benchmarks omiten. Y probablemente sea la más importante.
El resultado general: el podio es todo Qwen
Los tres primeros puestos fueron:
- Qwen 3.5 Dense
- Opus-Distilled
- Qwen 3.5 MoE
La lectura obvia sería intentar convertir esto en una narrativa geopolítica. Pero sería una mala interpretación.
No es una historia de China ganando a Estados Unidos. En la prueba había modelos chinos que dominaron… y otro modelo chino que terminó último. También había gigantes estadounidenses que quedaron en la mitad baja. Y Europa, en la práctica, apenas tuvo visibilidad competitiva.
La lectura correcta es otra: Qwen, como arquitectura, estuvo claramente por delante del resto.
Las sorpresas más importantes
El modelo más nuevo y más grande de Meta quedó cerca del fondo
Llama 4 Scout llegaba con mucho ruido mediático. Un fichero de 67 GB, 16 expertos, lanzamiento reciente, y el respaldo de Meta.
El resultado, sin embargo, fue flojo: Elo cercano a 800, un 28 % de win rate y un rendimiento especialmente pobre en tareas de síntesis. Su única fortaleza relativa fue la generación de código, lo que sugiere una optimización muy focalizada.
Lo llamativo es la comparación con Qwen 3.5 MoE: menos de la mitad de tamaño de descarga, mucha más velocidad y mejor calidad general.
El modelo de Google generó código roto
Gemma 3 produjo código Python con un bug de tipo KeyError que provocaba fallo en ejecución. A simple vista, el código parecía razonable. Pero al ejecutarlo, no funcionaba.
Ese es uno de los riesgos reales en producción: un modelo puede generar código incorrecto con total apariencia de solvencia. No basta con evaluar estilo ni legibilidad. Hay que ejecutar el código.
El modelo “de razonamiento” no razonó
DeepSeek R1 se presentaba como un modelo fuertemente orientado al chain-of-thought.
En la prueba matemática basada en criterio de Kelly, generó miles de tokens explicando el marco conceptual… pero sin llegar a calcular la respuesta.
En contraste, Phi-4, con menos de la mitad de parámetros, resolvió correctamente el problema en bastante menos texto.
La enseñanza es importante: hablar extensamente sobre razonamiento no equivale a razonar bien.
El chino sigue siendo una prueba exigente, incluso para modelos chinos
Solo un modelo obtuvo un 5-0 perfecto en comprensión de chino: Qwen 3.5 Dense.
Su propia variante MoE, con la misma base arquitectónica y los mismos pesos de partida, tuvo un desempeño muy inferior en esta tarea.
Esto apunta a una limitación estructural relevante de los modelos MoE: el mecanismo de routing puede penalizar capacidades multilingües complejas cuando ciertos expertos no cubren bien determinadas distribuciones lingüísticas.
Conclusión clara: si tu carga de trabajo depende de profundidad multilingüe y especialmente de chino, la arquitectura densa no es negociable.
El híbrido entre Anthropic y Qwen fue extraordinariamente fiable
Opus-Distilled combinó el conocimiento de Claude Opus con un cuerpo Qwen. El resultado fue el segundo mejor Elo global y, más importante aún, la mayor fiabilidad en pruebas de perturbación.
De hecho, superó al Qwen canónico en robustez. No solo preservó calidad: mejoró consistencia bajo variaciones del problema.
La implicación técnica es potente: la arquitectura importa tanto como el conocimiento destilado.
El campeón de calidad falló en precisión numérica
La sorpresa más incómoda del benchmark fue que Qwen 3.5 Dense, el campeón global, falló una prueba matemática perturbada por leer mal un valor numérico.
A partir de ese error inicial, construyó una larga cadena de cálculos internamente coherentes… pero basados en números equivocados.
Esto deja una lección crítica: un modelo puede liderar en Elo y aun así ser poco fiable en tareas donde la precisión numérica importa.
La conclusión real: no hay un mejor modelo
Ese es probablemente el mensaje más útil.
No hay un “mejor modelo” universal.
- El modelo con mejor calidad global puede fallar en precisión numérica.
- El modelo más rápido puede perder profundidad multilingüe.
- El modelo más fiable puede no ser el más eficiente en throughput.
Cada uno mostró fortalezas concretas y debilidades críticas. Y esas debilidades solo aparecen cuando se evalúa con tareas reales, comparaciones serias y perturbaciones controladas.
La pregunta correcta no es: “¿Cuál es el mejor modelo?”
La pregunta correcta es: “¿Qué modelo conviene para qué tarea?”
El siguiente paso: routing
La respuesta práctica no pasa por elegir un único ganador. Pasa por construir una capa de routing.
Un posible esquema operativo sería:
- Contenido en chino y análisis de máxima calidad → Qwen Dense
- Tareas rápidas en inglés, síntesis y extracción → Qwen MoE
- Precisión numérica y validación cruzada → Opus-Distilled
Todo ello ejecutándose en local, sin dependencia de APIs externas y sin coste variable por token.
Y a partir de ahí, el siguiente paso lógico es el fine-tuning específico por dominio: mejorar el MoE en cargas multilingües, reforzar el modelo denso en tareas estructuradas numéricas y usar el framework de evaluación como sistema de medición continuo.
Reflexión final
Los modelos ya son suficientemente buenos como para ser útiles en producción local. La diferencia real no la marca solo el modelo; la marca cómo lo evalúas, cómo lo enrutas y cómo lo integras en tu operación.
En otras palabras:
- el problema ya no es solo tener acceso a buenos LLMs.
- El problema es medir lo que de verdad importa.
Información basada en la publicación I benchmarked 8 local LLMs on DGX Spark. It’s not China vs. USA — it’s Qwen vs. everyone else.


