

El problema oculto de la IA multilingüe: más tokens, más coste
El coste oculto de usar IA en idiomas distintos al inglés. Se penaliza al español consumiendo Anthropic hasta 1.62x más tokens que en inglés.
Si una empresa usa IA en español, hay un coste que a menudo no está presupuestando bien: no basta con mirar el precio por millón de tokens; también hay que mirar cuántos tokens consume realmente cada idioma.
OpenAI explica que sus modelos pueden trabajar en muchos idiomas, aunque están optimizados para inglés, y además reconoce que el texto no inglés suele producir una ratio mayor de tokens por carácter.
Anthropic, por su parte, presenta a Claude como un sistema con rendimiento multilingüe fuerte en relación con el inglés.
- Consumo de tokens OpenAI en español frente al inglés: 1,18x
- Consumo de tokens Anthropic en español frente al inglés: 1,62x
- Esto es un 37% más de consumo frente a OpenAI en español.
La diferencia importante es esta: una cosa es entender bien varios idiomas y otra muy distinta es empaquetarlos con la misma eficiencia en tokens.
Ese matiz importa mucho más de lo que parece. Un trabajo académico sobre APIs comerciales mostró que hay lenguas que pueden necesitar hasta 5 veces más tokens que otras para transmitir el mismo contenido, y que esa fragmentación no solo encarece el uso: también reduce la utilidad del aprendizaje en contexto porque en la misma ventana de tokens caben menos ejemplos, menos documentos y menos instrucciones útiles.
Qué muestran las comparativas recientes
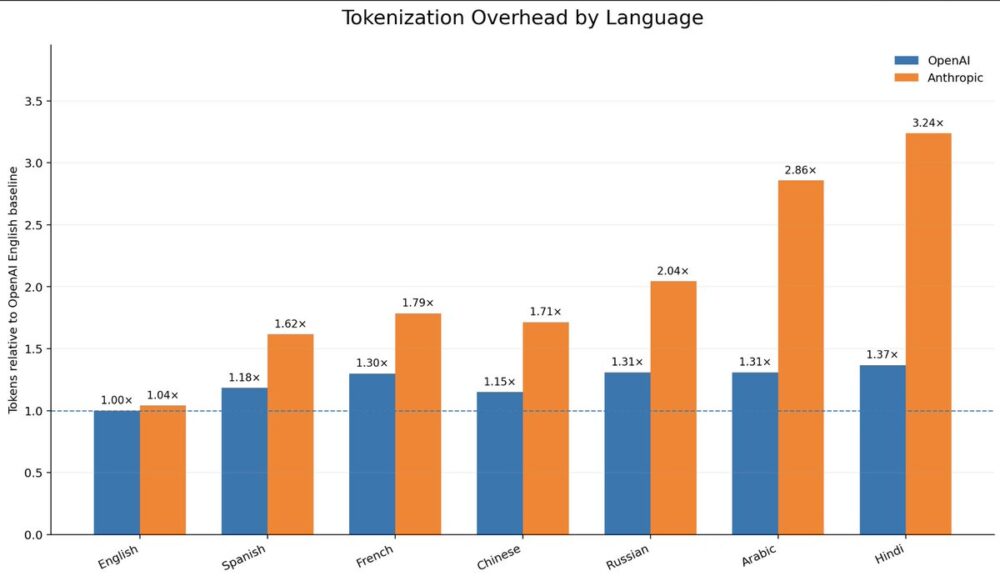
Las comparativas que compartes van justo al corazón del problema. En una medición difundida por Aran Komatsuzaki, a partir de traducciones del ensayo “The Bitter Lesson” de Richard Sutton1 y normalizada contra el conteo en inglés de OpenAI, el “impuesto no inglés” aparece con mucha más fuerza en Anthropic que en OpenAI:
- Hindi sale en 3,24x frente a 1,37x;
- árabe en 2,86x frente a 1,31x;
- chino en 1,71x frente a 1,15xM;
- español en 1,55x–1,62x frente a 1,18x.
No es una diferencia marginal: en esos idiomas, Anthropic consume claramente más tokens para expresar el mismo contenido.
La ampliación de ese análisis refuerza la misma idea y la vuelve más amplia: el chino sale incluso más barato que el inglés en varios modelos chinos; Gemini de Google y Qwen aparecen como los proveedores con menor penalización; Anthropic sale como el peor caso con diferencia y Kimi como el siguiente; e Hindi aparece como la lengua peor cubierta dentro de la muestra.
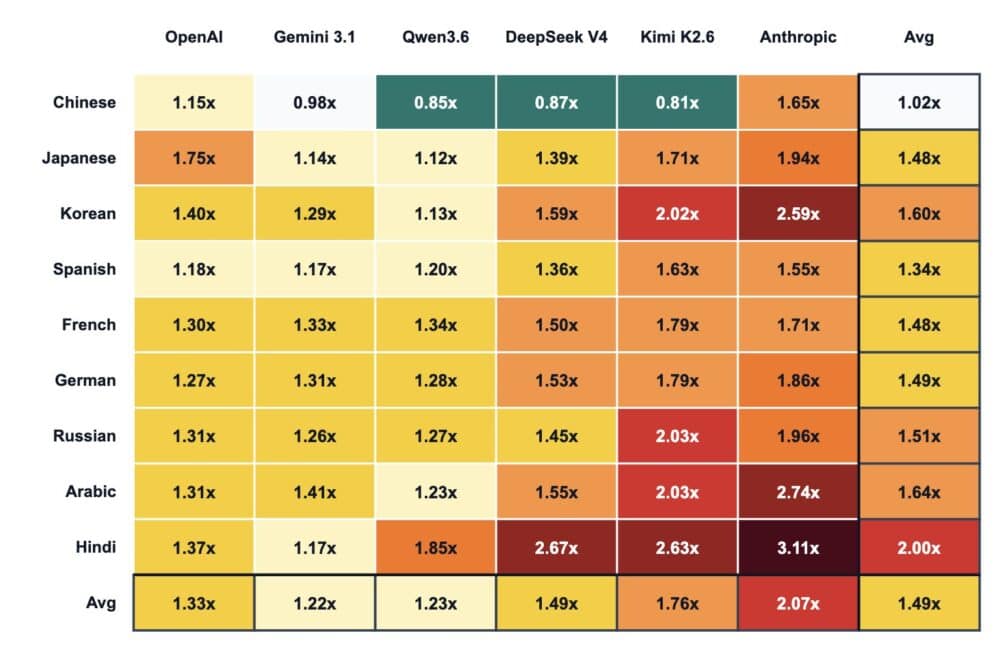
El español queda claramente penalizado: alrededor de 1,55x–1,62x en Anthropic frente a 1,18x en OpenAI, según la tanda exacta de medición.
La cifra cambia ligeramente entre las dos tablas, pero la historia no cambia: el español usa sensiblemente más tokens en Anthropic que en OpenAI.
Por qué Anthropic sale peor parado
La explicación más razonable no es que Claude “sepa menos español”, sino que la tokenización es menos eficiente para ciertos idiomas en ciertos modelos.
La literatura sobre tokenización multilingüe lleva tiempo señalando este patrón. Un estudio de 2025 sobre LLMs y ucraniano explica que las lenguas infrarrepresentadas en el vocabulario del tokenizer se vuelven más lentas y más caras porque el modelo procesa más fragmentos. Y el trabajo de Ahia y coautores sobre desigualdad de coste entre lenguas añade algo importante: la disparidad no se debe solo al reparto de datos de entrenamiento, sino también a propiedades propias de cada lengua y a cómo se representa en Unicode. Dicho de otro modo: hay un componente de diseño del tokenizer y otro de estructura lingüística.
Esto obliga a separar dos debates que a menudo se mezclan. Por un lado está la calidad multilingüe del modelo; por otro, la eficiencia económica con la que procesa cada idioma.
La propia documentación multilingüe de Anthropic publica resultados donde el español se mueve en torno al 98% del rendimiento del inglés en sus evaluaciones MMLU traducidas, lo que sugiere que Claude puede razonar en español con un nivel cercano al inglés. Pero esa cercanía en rendimiento no implica paridad en coste ni en compresión. Un modelo puede responder muy bien en español y, aun así, cobrarte más ventana de contexto y más tokens por hacerlo.
Además, las cifras de tokens no son una constante eterna ni siquiera dentro del mismo proveedor. Anthropic indica hoy en su documentación de precios que Claude Opus 4.7 usa un tokenizer nuevo que puede consumir hasta un 35% más de tokens para el mismo texto fijo. Eso no invalida las comparativas que compartes; al contrario, introduce una conclusión adicional: cuando hablamos de “impuesto lingüístico”, no hablamos solo de marca o de capacidad del modelo, sino también de la versión concreta del tokenizer que hay detrás.
Por qué importa en negocio
El impacto empresarial es directo porque ambas plataformas facturan en tokens. OpenAI explica que los tokens de entrada, salida, caché y razonamiento aparecen en los metadatos de uso y sirven para facturación y seguimiento. Anthropic, por su lado, publica sus precios base por millón de tokens de entrada y de salida. Si un idioma necesita más tokens para expresar lo mismo, el sistema procesa más unidades, tarda más en recorrerlas y consume más presupuesto relativo en la misma tarea. La penalización, por tanto, no es solo presupuestaria: también afecta a la latencia y al throughput.
También afecta a la cantidad real de información que cabe en la ventana de contexto. Anthropic ofrece hasta 1 millón de tokens de contexto en algunos modelos, pero una ventana larga no elimina la ineficiencia; solo la hace más cara a gran escala. Si tomamos los multiplicadores de tus gráficos como orden de magnitud, una tarea que en inglés “equivale” a 1,0 pasaría a ocupar 1,62 en español en una de las mediciones y 1,55 en otra. Eso significa que una ventana de 1M tokens se reduce, grosso modo, a unas 617.000–645.000 unidades equivalentes de información en inglés para esa misma tarea en español. Ahia y coautores ya mostraron precisamente este efecto: cuanto más fragmentada está una lengua, menos ejemplos entran en contexto y menos partido se saca del in-context learning.
Qué no conviene interpretar mal
Ahora bien, más tokens no significa automáticamente una factura final más alta que la de cualquier otro proveedor. El precio absoluto depende de la combinación entre tokens consumidos, modelo elegido y tarifa por millón de tokens. A día de hoy, OpenAI publica GPT-5.5 a 5 dólares por millón de tokens de entrada y 30 dólares por millón de salida; Anthropic publica Claude Sonnet 4.6 a 3 dólares por millón de entrada y 15 dólares por millón de salida. Por eso, un modelo con peor tokenización en un idioma concreto puede seguir siendo competitivo en dólares absolutos frente a otro con menos tokens pero con un precio unitario más alto. El “language tax” no sustituye una comparación seria de precio, calidad, latencia y contexto útil.
Tampoco conviene convertir este hallazgo en un titular simplón del tipo “Anthropic no sirve para español”. No es lo que dicen los datos. OpenAI afirma que sus modelos pueden operar bien en múltiples idiomas aunque estén optimizados para inglés, y Anthropic publica benchmarks en los que Claude mantiene un rendimiento relativo fuerte en español y otras lenguas. El problema no es la existencia de capacidades multilingües; el problema es que la economía del tokenizer sigue siendo desigual entre idiomas y entre proveedores.
Hacia dónde va la solución
La buena noticia es que este problema no parece una ley natural, sino una decisión de ingeniería mejorable. Un estudio de 2024 que evaluó tokenizers en las 22 lenguas oficiales de India encontró que un tokenizer específicamente diseñado para ese espacio lingüístico superaba a los demás en 14 idiomas. Es una señal importante: la penalización lingüística no es un destino inevitable; puede mitigarse con mejores estrategias de tokenización y mejor cobertura de vocabulario.
La investigación más reciente va, de hecho, en esa dirección. El trabajo sobre Parity-Aware BPE propone una variante de BPE que busca paridad de conteo entre idiomas y reporta mejoras claras en equidad sin degradar de forma sustancial el rendimiento downstream. Y Meta, con Byte Latent Transformer, plantea una vía todavía más ambiciosa: reducir la dependencia del tokenizer como preprocesado fijo y trabajar con bytes y parches dinámicos, consiguiendo rendimiento competitivo a escala. Son dos señales distintas, pero apuntan a la misma tesis: la industria ya está buscando formas de que el idioma deje de ser un peaje oculto.
Para cualquier organización que vaya a desplegar copilots, asistentes internos, automatización documental o RAG en español, la consecuencia práctica es muy clara: hay que medir en español, presupuestar en español y comparar en español. No basta con revisar benchmarks en inglés ni con asumir que “multilingüe” equivale a “coste-neutral”. La lección de fondo no es que los LLM no hablen español. La lección es más incómoda y más útil: todavía no lo comprimen con la misma justicia económica que al inglés.
Información basada en las publicaciones de Aran Komatsuzaki en X/Twitter: Traducción de The Bitter Lesson a múltiples idiomas y follow-up. Complementado con el estudio Parity-Aware Byte-Pair Encoding: Improving Cross-lingual Fairness in Tokenization.
- “The Bitter Lesson” es un ensayo muy influyente de Richard Sutton (2019) que resume una idea incómoda pero recurrente en la historia de la IA: A largo plazo, los métodos que dependen de computación y aprendizaje automático superan sistemáticamente a los que dependen de conocimiento humano diseñado a mano.
The Bitter Lesson dice: En IA, lo que escala (datos + cómputo) gana a lo que intentamos diseñar manualmente. Y en este caso concreto: La tokenización imperfecta de idiomas es el precio de esa decisión. ↩︎


