Comparativa de más de 40 modelos LLM en alemán
Malte Landwehr (Vice President of SEO at idealo) ha publicado una comparativa de más de 40 modelos de inteligencia artificial generativa en alemán.
El análisis lo ha realizado con más de 40 modelos utilizando el idioma alemán evaluando lógica y conocimiento del mundo real.
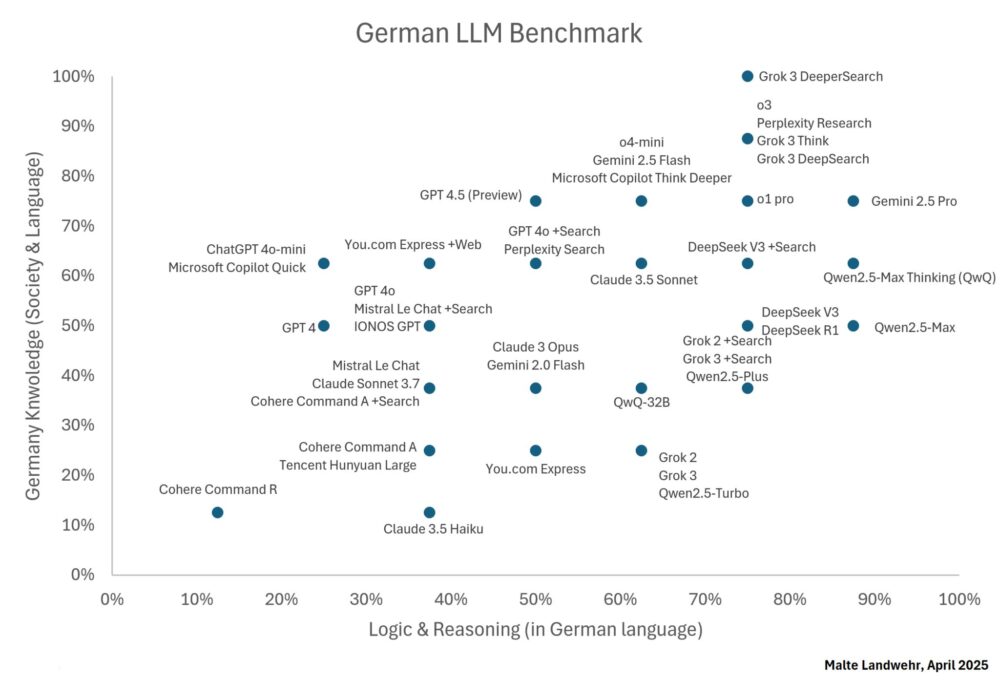
Aquí están los resultados más destacados:
Ranking General
- 🥇 Grok 3 DeeperSearch
- 🥈 Gemini 2.5 Pro
- 🥈 o3
- 🥈 Perplexity Research
- 🥈 Grok 3 Think
- 🥈 Grok 3 DeepSearch
Finalistas: o1 pro y Qwen2.5-Max Thinking (QwQ).
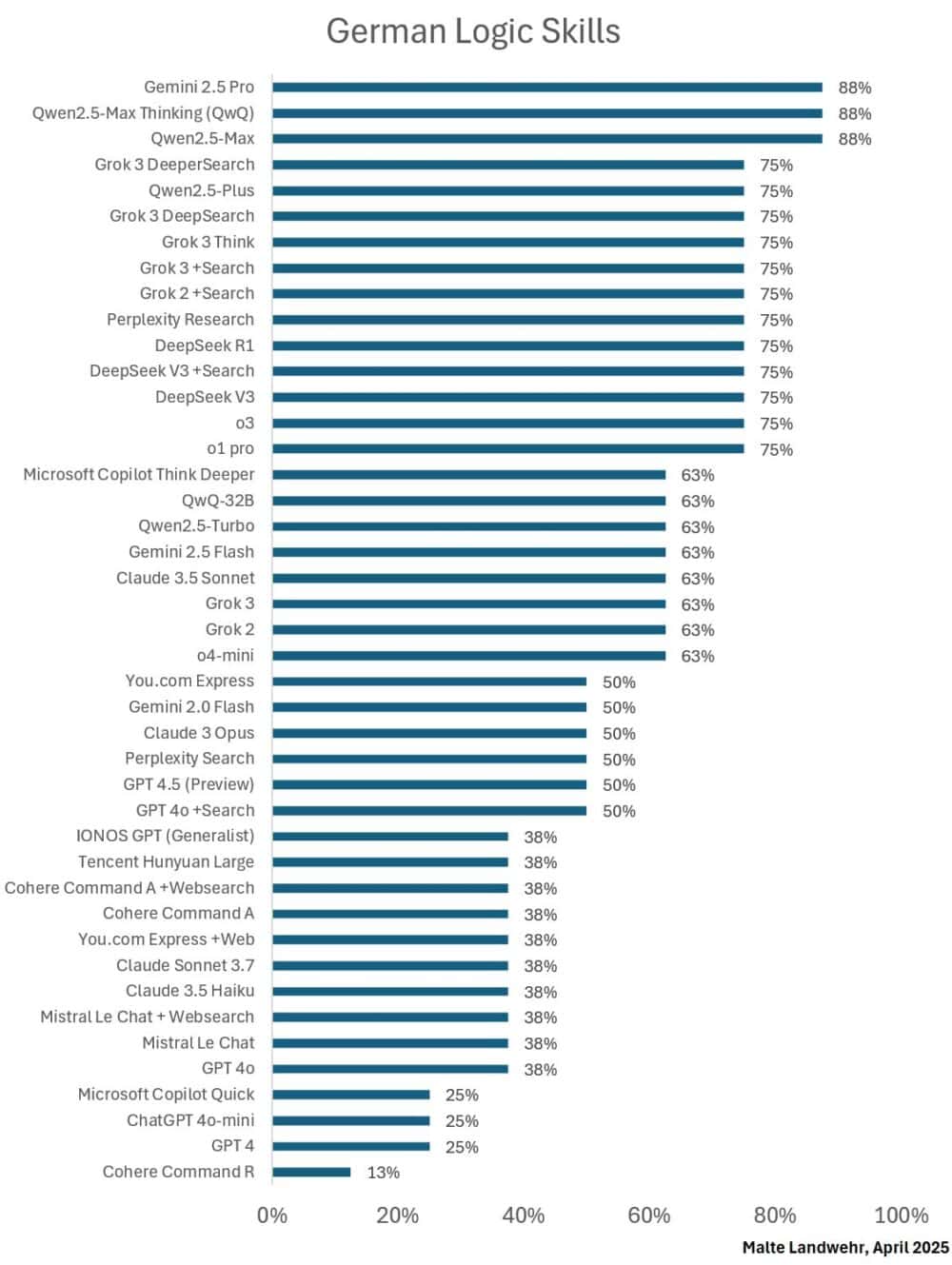
Lógica y razonamiento
- 🥇 Qwen2.5-Max
- 🥇 Qwen2.5-Max Thinking (QwQ)
- 🥇 Gemini 2.5 Pro
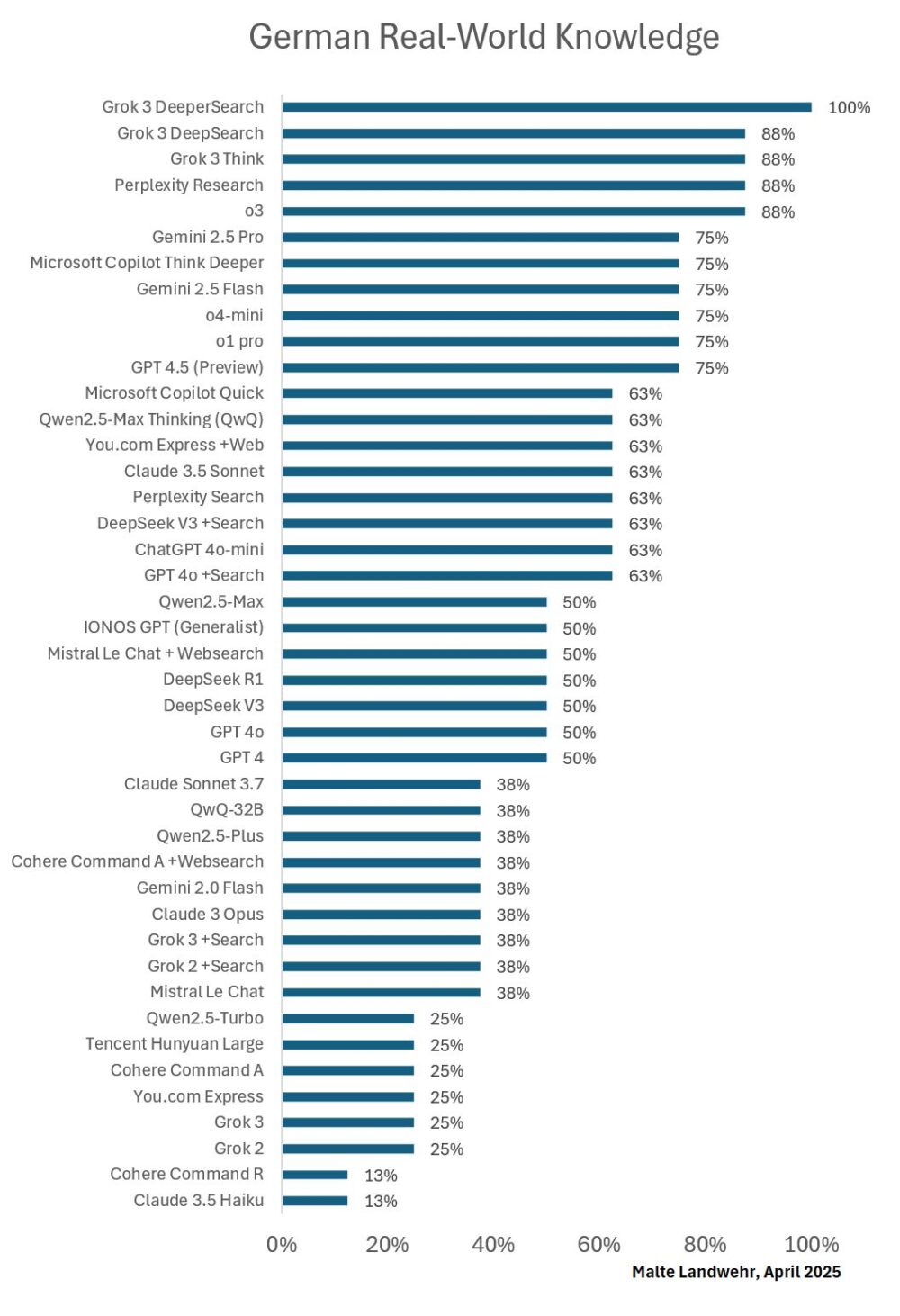
Conocimiento del mundo real en alemán
- 🥇 Grok 3 DeeperSearch
- 🥈 o3
- 🥈 Perplexity Research
Análisis por país de procedencia del modelo
- Estados Unidos 🇺🇸 domina en conocimiento del mundo real en alemán.
- China 🇨🇳 sobresale en lógica y razonamiento.
- Ninguno de los modelos del 50% superior es de la UE 🇪🇺 o Canadá 🇨🇦.
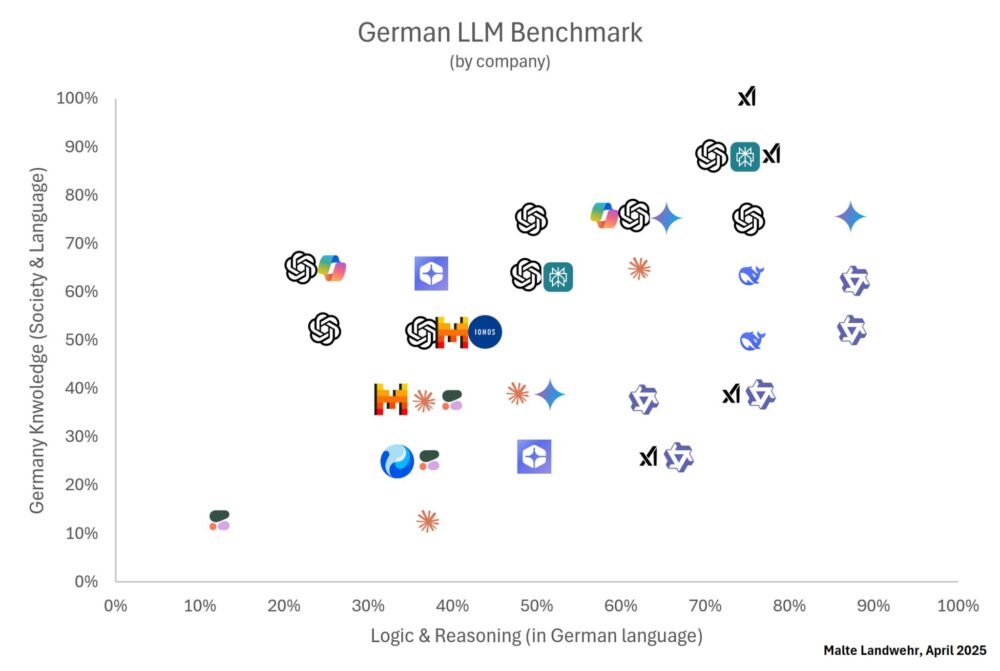
Análisis por empresa y familias de modelos
- Qwen (Alibaba) y Gemini (Google) destacan en razonamiento.
- OpenAI, xAI y Perplexity destacan en conocimiento del mundo real.
Algunas observaciones
- Al consultar costos de envío de cartas, los modelos chinos suelen asumir tarifas internacionales.
- La búsqueda es muy útil para responder preguntas del mundo real. ¡En algunos casos duplicó el rendimiento del modelo!
- La búsqueda puede perjudicar en razonamiento. Algunos modelos empeoraron al activarla, posiblemente por distraerse con información innecesaria.
Limitaciones
- ChatGPT Deep Research no funcionó adecuadamente en esta evaluación. Al plantear preguntas simples, o bien no hacía una investigación profunda o generaba un reporte demasiado amplio sin responder directamente la pregunta.
- DeeperSearch en Grok 3 es mejor que DeepSearch. ¡El nombre no es broma!
- Perplexity, Copilot, You y IONOS no utilizan modelos propios, sino que añaden funcionalidades sobre otros modelos. Los evalué en sus configuraciones predeterminadas para usuarios regulares.
Errores del ganador
- Grok 3 DeeperSearch solo falló 2 preguntas, ambas de razonamiento. • 16 modelos lograron responder correctamente al menos una de estas preguntas. • ¡2 modelos – Perplexity Search y Qwen2.5-Max Thinking (QwQ) – respondieron correctamente ambas preguntas! • Incluso Grok 2 con búsqueda y Grok 3 (con y sin búsqueda) respondieron correctamente una de ellas.
Conclusiones más relevantes
- El razonamiento intensivo y la incorporación excesiva de fuentes externas pueden confundir a los LLM y desviarlos del contexto original, ya suficientemente claro.
- Distintos modelos LLM destacan en distintas tareas. Al igual que con las personas, un consejo de varios LLM habría podido responder todas las preguntas correctamente.
- Una pregunta requería que el modelo afirmara que ninguna solución propuesta era válida. Que un LLM haga esto puede depender del «prompt» del sistema y del ajuste fino. Algunos modelos consideraron esta posibilidad, pero al final optaron por elegir una respuesta específica.
¿Cómo se realizó la evaluación?
Los criterios de evaluación son respuestas correctas a acertijos (lógica) y preguntas (conocimiento). Tanto los acertijos como las preguntas a veces evalúan la comprensión específica del idioma alemán.
Se le hace una pregunta al LLM cuya respuesta se conoce. Luego se califica la respuesta del LLM. Todas las preguntas tienen el mismo peso.
- Un conjunto de preguntas puede responderse mediante lógica y razonamiento. Todo el contexto necesario está en la pregunta, a veces de forma no evidente.
- El segundo conjunto incluye preguntas sobre la sociedad, leyes, costumbres e impuestos en Alemania, junto con algunas preguntas que requieren una comprensión adecuada del idioma alemán (doble negación que se puede reforzar o anular según el contexto, letras dobles vs triples, etc.).
Se formulan las preguntas específicamente en alemán porque algunas tienen matices que pueden perderse en la traducción.
Información basada en la publicación de Malte Landwehr (Vice President of SEO at idealo) en LinkedIn.