

¿Cuánto “alucinan” los diferentes modelos de lenguaje?
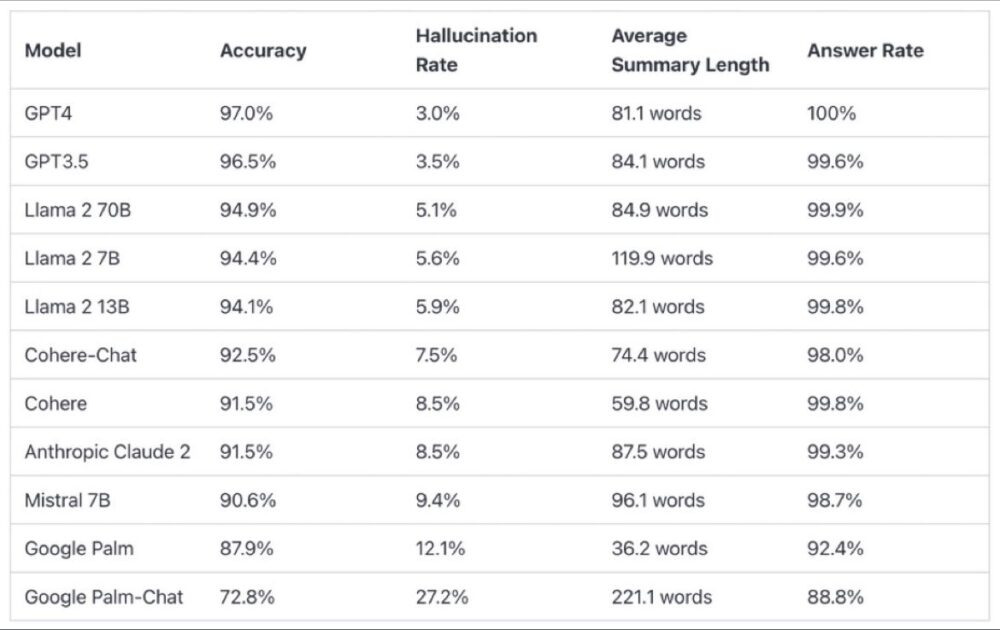
¿Cuánto “alucinan” los diferentes modelos de lenguaje? Según Vectara, los de #Google son los que mayor porcentaje de alucinaciones tienen. Los modelos que menos alucinaciones tienen, los de #OpenAI.
Metodología
Para determinar esta clasificación, entrenamos un modelo para detectar alucinaciones en los resultados de los LLM, utilizando varios conjuntos de datos de código abierto procedentes de la investigación sobre coherencia factual en modelos de resumen. Usando un modelo que compite con los mejores modelos del estado del arte, alimentamos 1000 documentos cortos a cada uno de los LLMs mencionados a través de sus APIs públicas y les pedimos que resumieran cada documento corto, usando sólo los hechos presentados en el documento. De estos 1.000 documentos, sólo 831 fueron resumidos por todos los modelos; los restantes fueron rechazados por al menos un modelo debido a restricciones de contenido. A partir de estos 831 documentos, calculamos la precisión global (ausencia de alucinaciones) y la tasa de alucinaciones (100 – precisión) de cada modelo. En la columna «Porcentaje de respuestas» se detalla el porcentaje de respuestas negativas de cada modelo. Ninguno de los contenidos enviados a los modelos era ilícito o «no apto para el trabajo», pero la presencia de palabras desencadenantes fue suficiente para activar algunos de los filtros de contenido. Los documentos procedían principalmente del corpus CNN / Daily Mail.
Evaluamos la precisión del resumen en lugar de la precisión general de los hechos porque nos permite comparar la respuesta del modelo a la información proporcionada. En otras palabras, ¿es el resumen proporcionado «factualmente coherente» con el documento fuente? Determinar las halucinaciones es imposible para cualquier pregunta ad hoc, ya que no se sabe con precisión con qué datos se entrena cada LLM. Además, tener un modelo que pueda determinar si una respuesta fue alucinada sin una fuente de referencia requiere resolver el problema de la alucinación y, presumiblemente, entrenar un modelo tan grande o más que los LLM evaluados. Por ello, decidimos analizar la tasa de alucinaciones en la tarea de resumen, ya que es un buen análogo para determinar el grado de veracidad de los modelos en general. Además, los LLM se utilizan cada vez más en las cadenas de RAG (Retrieval Augmented Generation) para responder a las consultas de los usuarios, como en Bing Chat y en la integración del chat de Google. En un sistema RAG, el modelo se despliega como resumidor de los resultados de búsqueda, por lo que esta tabla de clasificación también es un buen indicador de la precisión de los modelos cuando se utilizan en sistemas RAG.
Esta información está basada el Hallucination Evaluation Model visto en una publicación de LinkedIn de Alberto Pinedo Lapeña (National Technology Officer at Microsoft).
.


