DeepSeek-V3.1: Nueva versión de la IA open source china
El lanzamiento del enorme modelo open source chino está desafiando directamente el dominio de los gigantes estadounidenses de la IA.
La startup china DeepSeek lanzó ayer (21 de agosto de 2025) en Hugging Face su modelo más ambicioso: DeepSeek V3.1, un modelo de lenguaje de gran tamaño con 685.000 millones de parámetros.
DeepSeek-V3.1 ha recibido gran atención y las primeras pruebas revelan un rendimiento que rivaliza con sistemas propietarios de gigantes estadounidenses, cambiando el panorama competitivo gracias a su licencia open source y desafiando la economía establecida del desarrollo de IA avanzada.
¿Qué es DeepSeek-V3.1?
DeepSeek-V3.1 es un modelo masivo de 685.000 millones de parámetros, un aumento respecto a su predecesor de 671B. Ofrece una ventana de contexto de 128.000 tokens, al nivel de otros modelos abiertos como gpt-oss de OpenAI y Gemma 3 de Google.
Para mantener la eficiencia en tareas complejas, admite múltiples formatos de tensores (BF16, F8_E4M3 y F32), lo que permite optimizar el rendimiento según el hardware.
El modelo se basa en una arquitectura Mixture-of-Experts (MoE) que activa solo 37.000 millones de parámetros por token, reduciendo costes de inferencia pese a su tamaño total. Tiene un diseño híbrido que integra funciones de razonamiento y no razonamiento en un solo modelo. También se ha entrenado para uso nativo de herramientas, búsqueda y programación. Por defecto funciona en modo chat, pero puede cambiar a “pensamiento” y uso de herramientas añadiendo tokens especiales.
Este diseño contrasta con la generación anterior (DeepSeek-V2 y DeepSeek-R1), que separaba tareas normales y de razonamiento. DeepSeek parece haber resuelto problemas que afectaban a modelos híbridos anteriores.
DeepSeek-V3.1 se ha publicado bajo licencia MIT, lo que permite uso y modificación comercial. Está disponible en Hugging Face y en la API de DeepSeek a 0,56 $ por millón de tokens de entrada y 1,68 $ por millón de tokens de salida.

Resumen de Huggingface
DeepSeek-V3.1 es un modelo híbrido que admite tanto el modo de razonamiento (“thinking mode”) como el modo sin razonamiento. En comparación con la versión anterior, esta actualización aporta mejoras en varios aspectos:
- Modo híbrido de razonamiento: Un único modelo admite ambos modos cambiando la plantilla de chat.
- Llamadas a herramientas más inteligentes: Gracias a la optimización posterior al entrenamiento, el rendimiento del modelo en el uso de herramientas y tareas de agente ha mejorado significativamente.
- Mayor eficiencia en el razonamiento: DeepSeek-V3.1-Think logra una calidad de respuesta comparable a DeepSeek-R1-0528, pero respondiendo más rápido.
DeepSeek-V3.1 se ha entrenado posteriormente sobre la base de DeepSeek-V3.1-Base, que se construyó a partir del checkpoint original V3 mediante un enfoque de extensión de contexto largo en dos fases, siguiendo la metodología descrita en el informe original de DeepSeek-V3. Hemos ampliado nuestro conjunto de datos recopilando documentos largos adicionales y extendiendo sustancialmente ambas fases de entrenamiento.
- La fase de extensión a 32K se ha incrementado 10 veces, hasta 630.000 millones de tokens.
- La fase de extensión a 128K se ha ampliado 3,3 veces, hasta 209.000 millones de tokens.
Además, DeepSeek-V3.1 se ha entrenado utilizando el formato de datos UE8M0 FP8 para garantizar la compatibilidad con formatos de microscaling.
Descargas del modelo
La descarga está disponible en Hugging Face.
| Modelo | Parámetros totales | Parámetros activados | Longitud de contexto |
|---|---|---|---|
| DeepSeek-V3.1-Base | 671B | 37B | 128K |
| DeepSeek-V3.1 | 671B | 37B | 128K |
Rendimiento que rivaliza con los gigantes propietarios
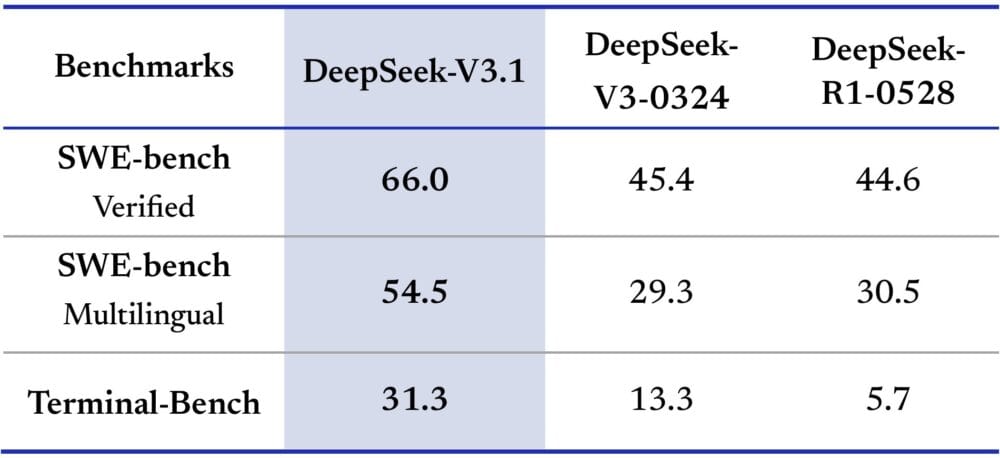
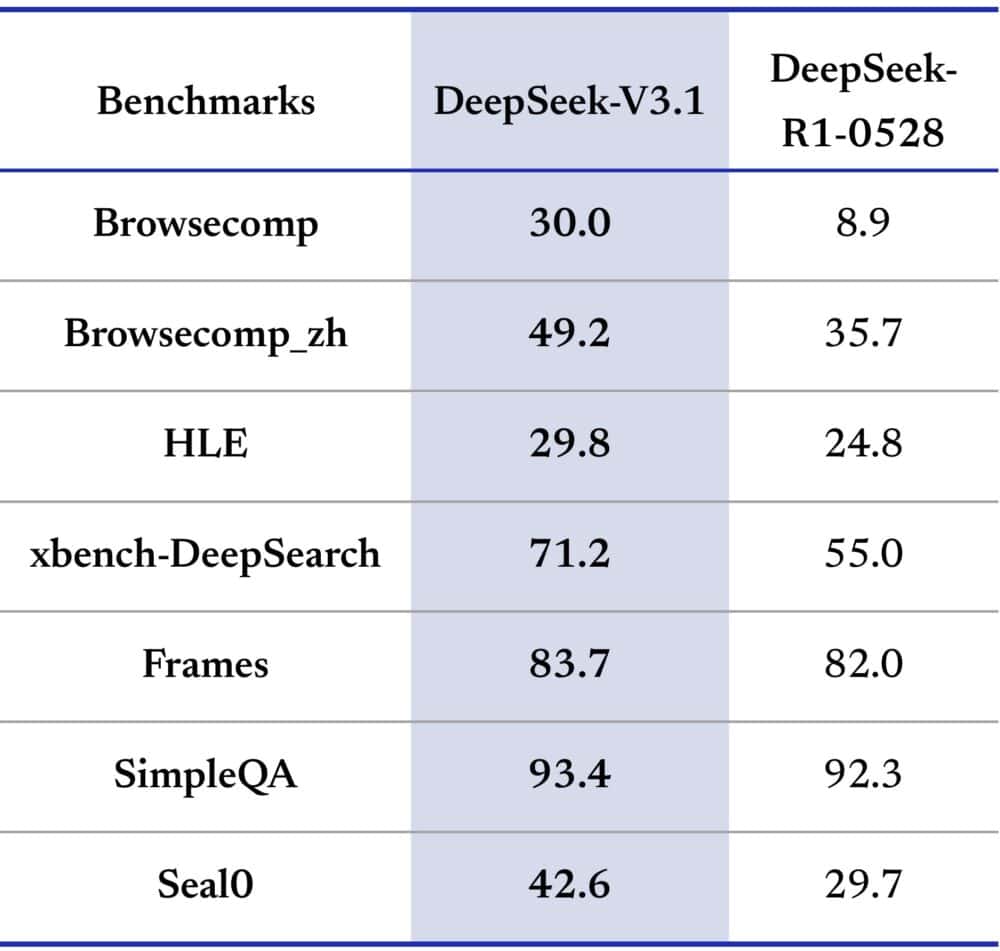
Los primeros benchmarks muestran que DeepSeek-V3.1 logra 71,6 % en la prueba Aider de programación, superando ligeramente a modelos propietarios como Claude Opus 4 de Anthropic y siendo mucho más barato. Según VentureBeat, el coste por tarea completa ronda 1,01 $, frente a casi 70 $ en sistemas equivalentes.
Más allá de la programación, muestra gran capacidad de razonamiento, resolviendo problemas lógicos complejos (como el famoso “balón rebotando en una figura en rotación”) y destacando en matemáticas, superando benchmarks como AIME y MATH-500.
Este ahorro se debe en parte a un bajo coste de entrenamiento: su predecesor, DeepSeek-V2, costó solo 5,6 millones de dólares por ejecución, muy por debajo de los laboratorios estadounidenses.
Un nuevo orden en el desarrollo de IA
El lanzamiento llegó semanas después de GPT-5 y Claude 4.1, desafiando los modelos cerrados y caros de EE. UU. Sam Altman (OpenAI) admitió que la competencia china influyó en su decisión de liberar modelos open weight.
Sin embargo, su tamaño (700 GB) es una barrera práctica: alojarlo y personalizarlo requiere recursos y experiencia que muchas organizaciones no tienen. Para la mayoría, la ventaja será el acceso a APIs más baratas, no la auto-implementación. Además, empresas estadounidenses podrían dudar por tensiones geopolíticas y preferencia por proveedores locales con soporte empresarial.
Un nuevo referente de potencia y accesibilidad
DeepSeek-V3.1 podría marcar un antes y un después, cambiando la carrera global de la IA: de quién construye el sistema más potente a quién lo hace más accesible.
El futuro de la IA dependerá del equilibrio entre potencia bruta y usabilidad práctica.
Información basada en las publicaciones oficiales de DeepSeek en Twitter/X (precios API y el anuncio oficial), la descarga del modelo en Hugging Face y el artículo DeepSeek-V3.1 is here. Here’s what you should know..