
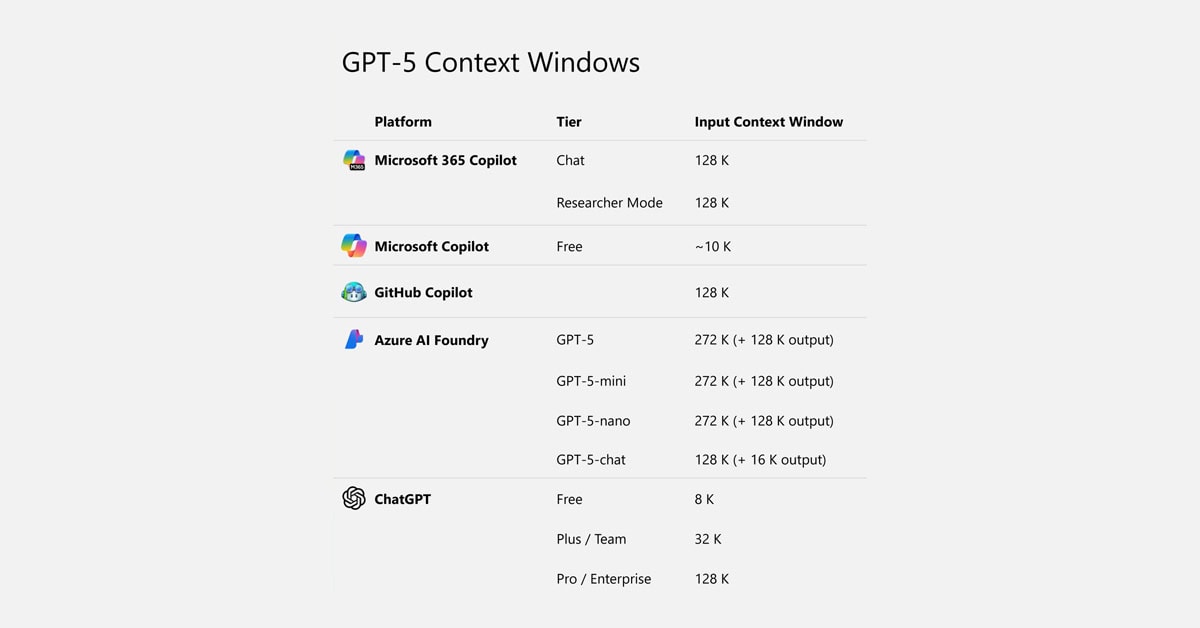
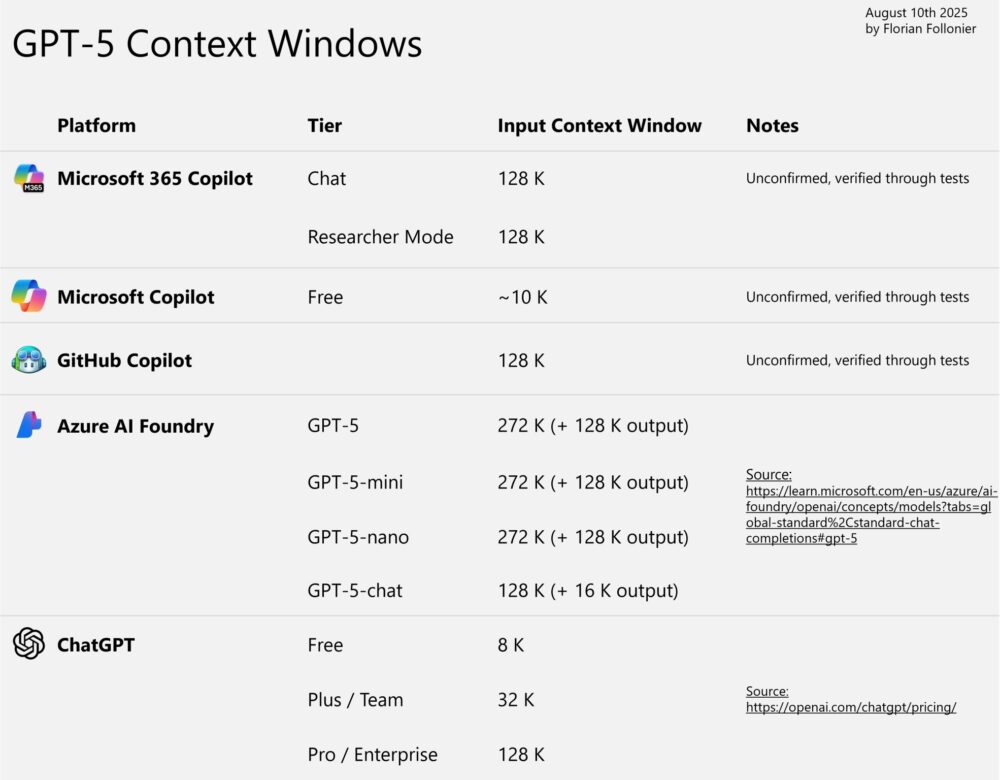
La ventana de contexto de GPT-5
Con la llegada de GPT-5 pensábamos que podríamos usar una ventana de contexto mucho más amplia pero se está viendo limitada.
Y sí, GPT-5 puede manejar hasta 272.000 tokens de entrada (+ 128.000 tokens de salida). Sin embargo, eso no significa que realmente puedas aprovechar todo ese potencial.
Microsoft 365 Copilot, GitHub Copilot, Azure AI Foundry y ChatGPT tienen límites diferentes, y muchos están muy por debajo de la capacidad máxima del modelo.
¿Por qué? El tamaño del contexto afecta al rendimiento, la latencia y el coste. Por eso, limitarlo en ciertos productos o niveles es una forma de gestionar la capacidad y la creciente demanda.
A medida que crece la adopción de GPT-5, es posible que veamos aumentos en estos límites en futuras actualizaciones, desbloqueando más capacidades del modelo.
Pero por ahora, si quieres aprovechar toda la ventana de contexto, despliega GPT-5 a través de Azure AI Foundry y utilízalo mediante la API.
Pero OJO: Azure Foundry tiene ahora mismo (12 de agosto de 2025) un límite de 20.000 tokens por minuto, y solo se puede aumentar mediante solicitud. Esta limitación, probablemente se aplique porque el modelo está disponible actualmente solo en Suecia Central y EAST US 2. Esperemos que el límite de velocidad aumente a medida que esté disponible en más regiones.
Y si te lo preguntas: 128.000 tokens equivalen aproximadamente a 96.000 palabras, lo que serían unas 320–380 páginas de texto. Así que 272.000 tokens equivalen a unas 700–800 páginas (basado en ~0,75 palabras por token y 250–300 palabras por página).
Información basada en la publicación en LinkedIn de Florian Follonier, PhD (Sr. Partner Solution Architect for Cloud & AI @ Microsoft).


